프로젝트 링크 : https://github.com/GoogleChrome/puppeteer/
첫번째 프로젝트는 구글 크롬 프로젝트에서 Headless Chrome Node API 로 내 놓은 퍼펫티어다. 퍼펫이라고 하면 번역하면 인형술사이고 꼭두각시 인형을 다루는 사람을 이야기 한다. 이 프로젝트의 배경부터 이야기 하자면 올해(2017년) 4월 경 구글프로젝트에서는 크롬에 Headless 모드를 추가했다.
Headless 브라우저라고 하면 일반적으로 CLI환경에서 브라우저가 시각적으로 보여지지 않고 백그라운드에서 작동할 수 있는 것을 이야기 하는데, 이 전까지 가장 유명한 것은 PhantomJS라는 프로젝트였다. 크롤링을 하고 스크린 샷을 찍어서 다운로드하고 등의 일들을 할 수 있었다. 그래서 데스크탑이 아닌 서버에서 DOM을 읽어야 하는 경우 등에서 많이 사용되고는 했었다.
필자의 경우는 테스트 환경을 꾸밀 수 있지 않을까 하는 기대에 관련된 작업들을 진행해 보았고 관련되어 링크를 남기기도 했다.
링크 : 헤드리스 크롬과 selenium2의 조합을 사용해 보자 with node (http://keen.devpools.kr/2017/06/07/about-test/ )
그런데, 8월 한달 가장 주목받은 프로젝트가 된 이 puppeteer는 Node.js에서 헤드리스 크롬을 사용할 수 있는 API들을 제공하는 것이다. Headless 모드를 발표하자마자 Phantom.JS는 더 이상 개발 안하기로 선언을 한 것과 마찬가지로 Node.js 진영에 새로운 무기가 생겨버린 셈이 되었다
1. 설치를 해보자
먼저 프로젝트를 한번 만들어 보자.
|
|
이렇게 설치를 하고 나면 프로젝트에 index.js 파일을 만든다..
<코드>index.js
|
|
스크린샷을 가져 오는 코드가 작성되었다. 개발바보들 첫 페이지의 스크린 샷을 가져오는 소스 코드를 작성한 이후에 node index.js 명령어를 입력하면 다음과 같은 이미지를 가지고 오는 것을 볼 수 있다.
기본적으로 지정된 이미지 크기는 800*600으로 지정된 듯 하다. 보통 phantomJS 같은 경우는 스크롤을 다 잡아 가던 초반 모습에 비해 메모리 관리를 위한 것인지 이미지 해상도도 그렇게 좋은 거 같지는 않아 보인다.
PDF로 Export 하는 기능도 API를 통해 구현이 가능하다.
2. 크롤링을 해 보자.
이번엔 find.js 라는 파일을 아래와 같이 만들어 본다. 실제로 이미지와 지금 아래 크롤링 소스는 해당 프로젝트와 내용이 거의 유사하다.
|
|
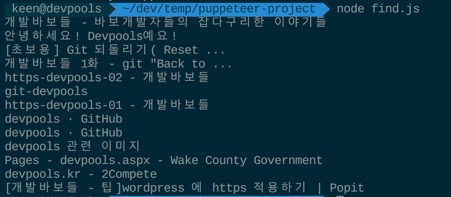
소스 코드에 대한 설명은 주석에 달아 둔데로 브라우저 객체와 페이지 객체를 만들고 구글 검색창을 방문해서 개발 바보들에 대한 검색어를 입력하고 검색버튼을 누른 뒤 검색된 결과의 타이틀을 가져와서 콘솔에 출력한다.
그 결과는 다음과 같다. 이 과정 중에 어떤 브라우저의 인터렉션도 필요 없었고 (내부적으로는 크롬 헤드리스 브라우저가 작동을 했지만) 사용자의 경우는 결과만 가져올 수 있다.
맺음말
왜 구글은 이런 제품을 내놓고 있는 걸까? 워낙 혁신적인 기업이라 속내를 다 살펴볼 수는 없지만 지속적으로 API를 내놓고 있는 것은 웹의 많은 부분이 자동화로 돌아설 것이고 그 중심에 인공지능이 있지 않을까 하는 생각이 들어 잠시 한번 고민을 해 보았다. 아마도 텐서플로가 조만간 DOM 기반의 러닝 모델을 공개하는 날이 오지 않을까?