2018년 6월 2~3일 양일간 JavaScript 최대 컨퍼런스인 JSConf 유럽 행사인 JSConf EU 가 개최되었다. 필자는 가보지 못했지만 , TC39 패널도 나오고 Remy Sharp 도 발표자로 나오고 하니 볼만한 컨퍼런스였던 거 같다. (TC39는 ECMAScript – 즉 JavaScript 의 표준을 정하는 단체다. Remy Sharp 는 nodemon, jsbin 의 개발자로 유명하다.)
하지만, 지금 들려오는 최고의 이야기는 deno 에 대한 이야기이다. 이 프로젝트가 공개된지 20여일만에 깃헙 스타를 2만개를 어떻게 받았을지 한번 알아보도록 하자.
그림 1. JavaScript 최고의 컨퍼런스
JSConf.EU에서 라이언 달(Ryan Dahl)은 첫날 저녁 세션에서 "10 Things | Regret About Node.js" 라는 제목으로 발표했다.
그림 2. 개발자의 완성은 얼굴
유튜브 링크 : https://www.youtube.com/watch?v=M3BM9TB-8yA
pdf 링크 : http://tinyclouds.org/jsconf2018.pdf
라이언 달은 Node.js 를 처음 만든 사람으로써 현재 가장 큰 오픈소스 커뮤니티 중 하나인 노드 커뮤니티의 첫번째 리더였다. 그가 이번에 발표한 것은 그동안 사람들이 많이 제시한 부분을 어느 정도는 이야기 하고 있다는 점에서 주목해 볼만하다. 10가지 이야기를 살펴보자
이야기의 배경
처음 라이언 달이 노드를 만들때는 이벤트 드리븐 HTTP Server를 만들고 싶었고 거기에 가장 적합했던 것이 당시 JavaScript 였고 그 목표는 훌륭하게 달성했다고 한다. (Node.js는 이 말 대로 가장 빠르게 인기를 얻은 서버사이드 프레임워크가 되었고 이 사상은 이후 다른 언어에 영향을 끼치게 된다.)
하지만, 최근에 학술적인 컴퓨팅 작업을 하면서 버그들이 명확하지 않다라는 사실을 알게 되었고, 이번의 작업을 하게되었다고 한다.
10가지 이야기
- Promises 로 갔어야 했는데…(Not sticking with Promises)
아마 Node.js를 작업하는 대부분의 사람들은 이 말에 백퍼공감 할 것 같은데, Node.js 의 비동기 호출은 여전히 콜백 API를 기준으로 되어 있다. Promises는 Async, Await 을 제공하기 위해서는 필수라고 할 수 있다. 2009년에 추가했다가 2010년에 지운 일에 대해서 언급하면서 자신이 Promises를 고집했다면 커뮤니티 소스가 더 빨리 Async Await으로 진보했을 것이라는 후회
- 보안 문제 더 신경쓸 걸( Security )
V8은 그 자체로 훌륭한 샌드박스 모델을 가지고 있다는 것과 이후 Node 응용 프로그램이 어떻게 유지되고 발전되는 것을 고려했었으면 다른 언어들이 갖지 못할 보안을 가질 수 있었을 걸 하는 후회를 남겼다.(V8은 Node.js의 JavaScript 엔진으로써 구글에서 만들어 크롬에도 사용된다.)
- 빌드시스템(GYP) -1
처음 노드를 만들때 크롬 브라우저가 GYP라는 메타 빌드 시스템을 사용하다가 크롬은 GN 으로 메타 빌드 시스템을 업그레이드 했는데 Node.js 는 GN으로 변경하지 못한 부분에 대한 이야기를 한다. 참고로 구글의 GN을 소개하는 시스템에서는 20배 정도 빠르게 빌드가 된다고 한다.( 메타 빌드 시스템은 여러 플랫폼-윈도우즈,Mac, Linux-에서 소스코드를 빌드하기 위해서 사용되는 빌드 시스템이다.)
- 빌드시스템(GYP)-2
GYP를 이용해 빌드 시스템을 만들면서 네이티브 콜을 하기 위해서는 C++ 바인딩을 하도록 사용자에게 강제 했는데, FFI(Foreign Function Interface) 를 제공했었어야 되었다고 하는 이야기를 한다.
- 패키지 매니저 파일(package.json) -1
Node.js 는 모듈 시스템을 가지고 있다. 이 모듈 시스템을 go 와 java에서 최근에 언어 자체적으로 구현이 되는 스펙들이 발표가 되었다. (go는 나오면서 부터) 하지만, 이 모듈 시스템을 관리하는 프로그램은 3
rd
파티 프로젝트로 최근에는 떼어 놓는 것이 일반적인데 노드는 npm이라는 패키지 매니저가 관리하는 package.json. 파일이 main() 함수에서 찾도록 함으로 npm 의존적으로 커뮤니티를 만든 점을 스스로 비판하고 있다. 최근에는 facebook에서 만든 yarn이라는 패키지 매니저가 npm을 대체하고 있지만 package.json은 그대로 사용하고 있다. 의도하지 않았지만 defacto(사실상의 표준)이 된 셈.
또, 이 package.json 파일은 모듈을 찾을 때 명시적이지 않은 단점도 존재한다. 아래 그림을 참조하면 이해가 될 것이다.
그림 3. somemodule을 찾아라!(출처 : http://tinyclouds.org/jsconf2018.pdf )
- 패키지 매니저 파일 (package.json) -2
package.json 파일의 모듈 시스템이 파일 디렉토리 기준으로 잡혀 있게 만들어서 package.json 파일이 현재는 라이센스, 레파지토리, 설명등을 비롯해서 모듈 시스템 자체만으로는 필요없는 정보를 다 가지게 되어서 너무 무겁게 된 경향이 있다고 한다.
- 모듈 시스템(node_modules )
위에서 언급한 파일 디렉토리 기반의 모듈 시스템의 약점과도 일맥상통하게 모듈을 가져오는 알고리즘이 복잡해졌고, 브라우저에서 가져오는 방법과도 맞지 않기 때문에 굉장히 어려워 졌다는 이야기를 하면서 그렇지만 이것은 돌이킬 수 없기 때문에 커뮤니티에 미안하다는 의견을 피력했다.
- Require 문법을 쓸 때 js 확장자를 안써도 되게 한 점.
이것은 오히려 브라우저내 자바스크립트가 작동하는 것과 표준이 달라서 모듈로더는 사용자의 의도를 파악하기 위해 많은 고민을 해야 한다는 점을 이야기 했다.
- index.js
브라우저가 index.html을 default로 가지기 때문에 index.js 를 지정한게 그 때는 괜찮다고 생각했으나 모듈로딩 시스템을 더 복잡하게 만들었다고 한다.
deno
이상의 10가지 이야기를 마지막으로 자기가 새로 만들고 있는 프로젝트를 공개했는데 그게 바로 이 deno 프로젝트다.
프로젝트 링크 : https://github.com/ry/deno
그림 4. 무려 TypeScript Runtime
아직은 프로토타입 같이 시작에 불과한 프로젝트지만 이런 작은 소스코드가 얼마나 커지는 지를 그동안 Node.js를 통해 우리는 잘 보아 왔다.
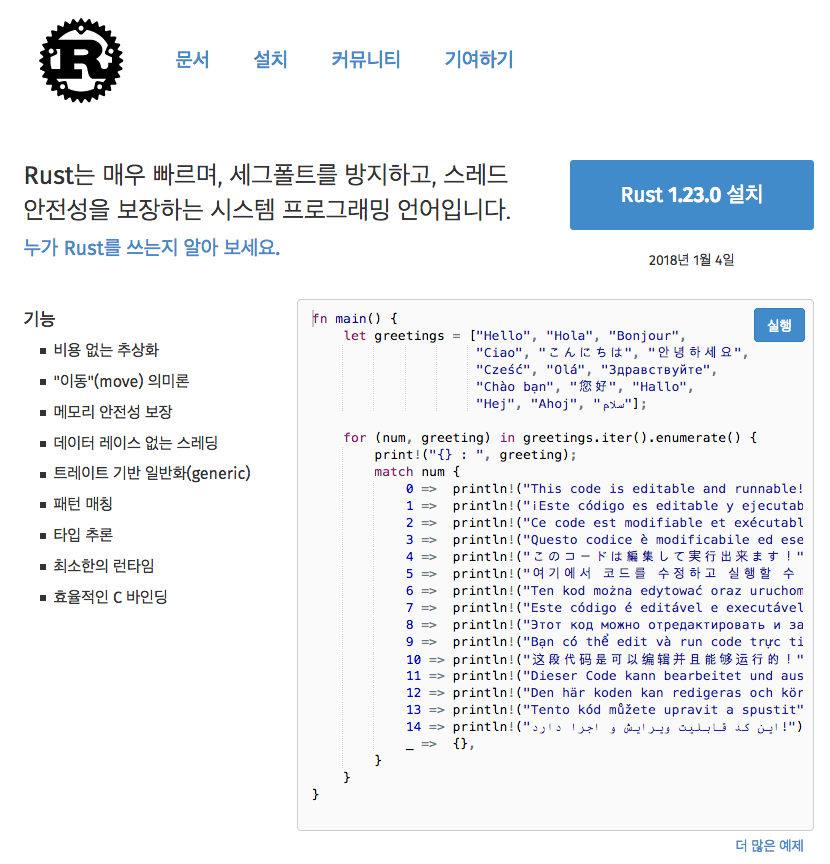
가장 기본적인 특징은 TypeScript를 Runtime 으로 가진다는 것이다. 트랜스 파일이 아니라 바로 런타임 지원이라는 것이 중요한 특지이다.
package.json 없고 npm 없고 source code url 만 import 할 수 있다. 다음을 보자.
import { test } from "https://unpkg.com/deno\_testing@0.0.5/testing.ts"
import { log } from "./util.ts"
require 가 아니라 import 명령어를 사용하고 확장자 .ts를 지정하며 url 임포트를 한다.
파일시스템과 네트워크는 샌드박스 모델을 사용해서 그냥 사용할 수는 없고 인터페이스를 통해서만 가능하고 현재는 프로토콜 버퍼를 통해 V8 엔진과 인터페이스 할 수 있다. 빌드 스크립트에는 gn과 ninija를 사용한다.
그림 5. gyp 안녕
그 외에도 자기가 후회하는 것들을 모두 바로 잡아 두었음을 알 수 있다. 흥미로운 것은 golang 브랜치를 가지고 있다는 것이다.
그림 6. 어디에 쓰는 브랜치인고
브랜치로 가보면 go 로 빌드하는 인스트럭션이 나와 있는 걸로 봐서는 go 빌드를 중간에 고려했다가 gn으로 선회한 것으로 보인다. 혹시 틀렸으면 멘션 주시면 반영하겠다.
맺으며
아직은 조금 더 두고 봐야하는 프로젝트겠지만 아마도 Node.js 진영에서 이 변화를 강건너 불 보듯 하고만은 있지는 않을 것 같다. 현재는 Node.js. 에 합칠 수 있어보이지 않기 때문에 긴 시간의단련은 필요해 보이지만 서버사이드 스크립트 엔진의 새로운 시작이라고 보여지고 계속 주목해 보아야 하겠다.
]]>